









Még alig telt el egy hét az újévből, az IT-biztonság világát máris egy csokornyi, eddig nem látott jelentőségű sebezhetőségről szóló hír rázta meg. A Spectre és Meltdown névre keresztelt két problémakör egymással összefüggő, de különböző módszerekkel kiaknázható hibákat takar. Feltárásukban a Google Project Zero tagjai, a Grazi Műszaki Egyetem, a Marylandi Egyetem, a Pennsylvaniai Egyetem és az Adelaide Egyetem munkatársai, illetve független szakértők is részt vettek.

Súlyosságukat mutatja, hogy noha legkésőbb 2017 júniusában megtalálták őket, mégis csak több mint fél év késéssel, 2018 elején kerültek a szélesebb nyilvánosság elé. Ha hihetünk a pletykáknak, a felfedezők még egy kicsivel tovább titokban szerették volna tartani ezeket a hibákat, ám néhány napja elkezdtek fontos információk szivárogni azok technikai részleteiről, így nem lett volna értelme a további titoktartásnak. A némileg megkurtított türelmi idő alatt is volt már lehetősége több érintett – és beavatott – technológiai nagyvállalatnak, többek között az Apple-nek is, részleges javításokat, biztonsági frissítéseket fejlesztenie.
TL;DR (túl hosszú, nem olvasom végig)
Két súlyos, egymással összefüggő biztonsági hibát fedeztek fel, amely csaknem minden olyan készüléket érint, amely az utóbbi 15-20 évben gyártott processzorral rendelkezik. Az esetben iPhone, Mac és Apple TV készülékek is érintettek, de az Apple Watch nem. A hibák teljes befoltozása az informatika történetének egyik legnehezebb és leglassabb javítása lehet, mindazonáltal a fokozatosan megjelenő, részleges biztonsági frissítéseket mindenkinek érdemes felraknia.
Miért “ég a ház”?
Sok helyen olvashatjuk-hallhatjuk azt a frázist, hogy a Spectre minden idők legsúlyosabb biztonsági hibája lehet. Vajon mi ad okot egy ilyen erős állítás megfogalmazására?
A helyzet komolyságát két tény alapozza meg. Az egyik az érintett készülékek, processzorok száma, ezáltal egy lehetséges támadás kiterjedtsége. A Spectre gyakorlatilag minden, modernnek mondható processzort érint, a rajtuk futó operációs rendszertől függetlenül. A két legnagyobb gyártó – az Intel és az ARM – processzorai, valamint mások, például az AMD által készített chipek is sebezhetőek. Az asztali gépek és laptopok többségében nagyteljesítményű Intel, esetleg AMD processzorok ketyegnek, míg az ARM magokat általában okostelefonokban, tabletekben, valamint úgynevezett beágyazott rendszerekben találhatjuk meg. Jó eséllyel a kedves autóvezető olvasók járműveiben is elrejtettek egy vagy több, ARM-alapú fedélzeti számítógépet…
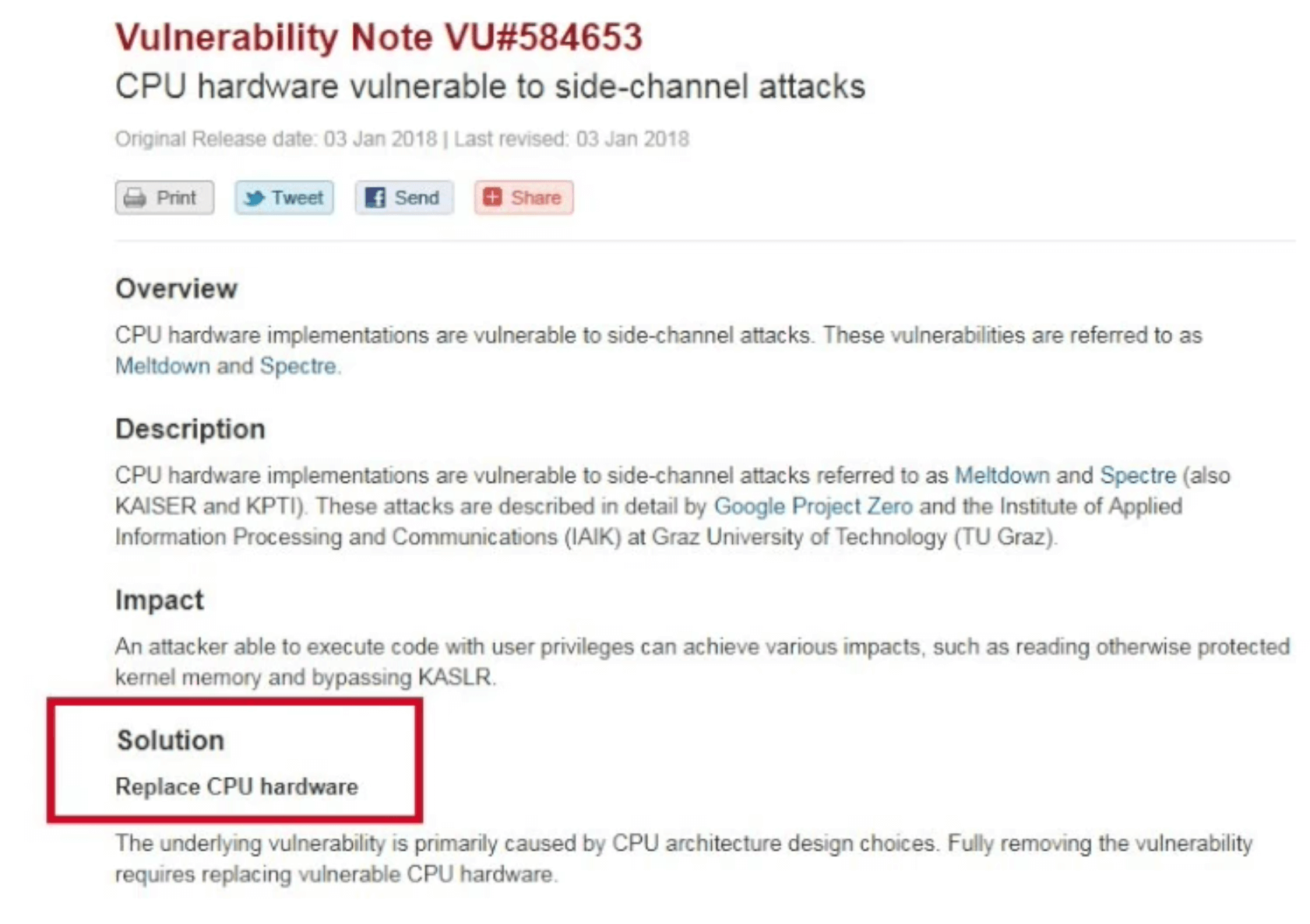
A probléma súlyosságának másik forrása az, hogy nem egy egyszeri, jól körülhatárolt, egyetlen szoftverfrissítéssel orvosolható hibajelenséggel állunk szemben. A Spectre levezethető a modern processzorok tervezéséből, architektúrájából, tehát jó közelítéssel egy univerzális hardverhiba. Bizonyos kihasználási módjai ellen létezik szoftveres védelem is, de teljes megoldást csak új CPU-k tervezése, gyártása és széleskörű elterjedése jelentene. A CERT sérülékenységi adatbázis oldalán például eleinte csak az alábbi szűkszavú “megoldás” volt látható:
A Meltdown esetében valamivel jobb a helyzet: az ezt kihasználó exploit főleg az Intel és részben az ARM processzorokat támadja; eddig úgy tűnik, hogy az AMD processzorai immunisak rá. Emellett a Meltdown javarészt szoftveresen korrigálható: a legfrissebb Linux kernelben és a macOS 10.13.2-es verziójában már javították is, noha ez a megoldás sem fenékig tejfel, mert egyes programok futását akár 30 százalékkal is lelassíthatja.
Az Apple is kiadott egy közleményt, amelyben leírja, hogy az iOS, a macOS és a tvOS is érintett a két biztonsági résben, viszont a watchOS nem. A hibajavításra szoruló három almás operációs rendszerhez pedig hamarosan a problémát legalább részben orvosló frissítéseket tesz elérhetővé a cég.
No de ne szaladjunk még ennyire előre.
Mindent a sebességért
Nézzük meg kicsit részletesebben, mi is a Spectre és a Meltdown alapját képező tervezési hiba.
Az elmúlt két évtizedben a processzorgyártók szoros versenyben álltak egymással a vásárlók kegyeiért, és mindenki igyekezett a leggyorsabb, legokosabb, legnagyobb számítási kapacitású chipeket előállítani. Ennek egy módja volt a processzoralkatrészek fizikai méretének csökkentése, ami növelte a megengedett maximális órajel-frekvenciát. A fejlődés ezen irányának azonban mostanra gátat szabott a fizika: az alkatrészeket nem lehet a végtelenségig zsugorítani, praktikusan pár atomnál kisebb tranzisztort nem lehet készíteni. A hardvertervezőknek tehát más módszerekhez kellett folyamodniuk.
A nyers órajelsebesség továbbnövelése helyett arra összpontosítottak tehát, hogy az egy órajelciklus alatt elvégzett munkát tegyék minél hatékonyabbá. Ennek a legkézenfekvőbb módja a párhuzamosítás: a manapság elterjedt CPU-k szinte mindegyike több utasítást hajt végre adott idő alatt, mint ahány órajelet kap. Leegyszerűsítve, egy utasítás végrehajtásának különböző lépései vannak: betöltés a memóriából (“fetch”), dekódolás (“decode”), azaz annak a megállapítása, hogy mit fog csinálni az utasítás, és az utasítás tényleges lefuttatása (“execute”). Minden ilyen végrehajtási lépést saját, dedikált, a többitől független áramkör végez. Ez azt jelenti, hogy amíg például az egyikük egy utasítást tölt be a memóriából, a másik azalatt már egy korábban betöltött utasítást dekódol. Ez a pipelining-nak nevezett technika az egyik legalapvetőbb párhuzamosítási módszer.
A processzor emellett az üresjárati időt is megpróbálja minimalizálni, amit megint másfajta párhuzamosítási trükkökkel ér el. Ha például egy utasításnak szüksége van egy adatra a RAM-ból, akkor arra elég sokat, akár több száz órajelnyi időt is kell várakozni. Ezalatt a processzor azonban igyekszik hasznossá tenni magát, és olyan utasításokat végrehajtani, amihez az érkezőfélben lévő adat nem szükséges. Ez azt jelenti, hogy a CPU adott esetben más időrendben hajtja végre az utasításokat, mint ahogyan azt a futó program megadta. Ezt a viselkedést angol szaknyelvi kifejezéssel úgy hívják, hogy sorrenden kívüli végrehajtás, azaz out-of-order execution.
A RAM lassú mivolta másfajta optimalizációs trükköket is életre hívott. Az egyik ilyen az úgynevezett CPU cache, avagy gyorsítótár használata. Ennek lényege, hogy a RAM-ból betöltött adatokat a processzor átmenetileg egy sokkal kisebb (pár kB vagy MB), de sokkal gyorsabb (néhány 100 helyett mondjuk 5-10 órajel alatt kiolvasható), magán a processzoron elhelyezett memóriába is átmásolja. A következő alkalommal, amikor az adatra szükség lesz, a lassú RAM helyett a gyors cache-ből fogja azt kiolvasni, ezáltal lecsökkentve a várakozási időt, és felgyorsítva az utasítások végrehajtását.
Újdonsült kedvenc sebezhetőségeink szempontjából még egy csokornyi, egymással összefüggő technikát fontos ismernünk, ez pedig a spekulatív végrehajtás és a branch prediction (mesterkélt magyar szakkifejezéssel “elágazásbecslés”. Brrrr!).
A számítógépek egyik fontos feladata a döntéshozás: egy programban nem mindig hajtódik végre minden utasítás, hiszen bizonyos feltételektől függően más és más viselkedésre van szükség. Például egy banki rendszer végrehajthat vagy elutasíthat egy átutalást attól függően, hogy van-e elég pénz a számlánkon. Az ilyen döntéshozatal úgy történik, hogy a memóriában lineárisan, egy hosszú sor mentén egymás után felsorakoztatott utasítások között a processzor ide-oda ugrik. A banki példánál maradva, lehetséges, hogy a sikeres átutaláshoz tartozó utasítások a memória elején, a 0-s címtől, míg az átutalás megtagadásához szükséges utasítássorozat mondjuk a 128-as címnél kezdődik. Ekkor a CPU meg tudja vizsgálni, hogy az egyenlegünk nagyobb-e az átutalás összegénél; ha igen, akkor a 0-s, ha nem, akkor pedig a 128-as címtől kezd el utasításokat végrehajtani. Ezt az ugrást hívják elágazásnak, angolul branch-nek, hiszen a program lehetséges kimenetele az ugrás célcímétől függően kettéágazik.
A szomorú valóság az, hogy az ilyesfajta ugrándozásnak komoly ára van. Az elágazások a fentebb már ismertetett pipeline optimalizációt ellehetetlenítik, hiszen az ugrás utáni utasításokat nem lehet addig a pipeline-ba pakolni és elkezdeni végrehajtani, amíg a branch utasítás kimenetét nem tudjuk biztosan, amihez pedig minden, az ugrás feltételét meghatározó adatnak készen kell álnia, az őket eredményező utasításoknak így teljes egészében végre kell addigra hajtódniuk. Ezáltal az elágazások csökkentik a pipeline kihasználtságát, azaz a párhuzamosíthatóság mértékét, tehát a processzor effektív sebességét is.
Ennek a kiküszöbölésére fejlesztették ki a branch prediction módszerét. Ez abban áll, hogy a processzor megpróbálja a múltbeli végrehajtások alapján megjósolni, hogy egy adott elágazás melyik irányba fog menni. A banki példánál maradva, ha egymás után sokszor utalunk át pénzt sikeresen, akkor a processzor el fogja tárolni azt az ismeretet, hogy valószínűleg a következő átutalás is sikerülni fog. Amikor egy ilyen megjósolt kimenetelű ugrás végrehajtására kerül a sor, a processzor még a tényleges feltétel kiértékelése előtt el fogja kezdeni azt az ágat végrehajtani, amelyikről úgy gondolja, hogy valószínűbb. Ez azonban egy elszigetelt környezetben, ha úgy tetszik, “homokozóban” történik, így amennyiben a jóslás hibázik, akkor a CPU a fölöslegesen végrehajtott utasítások minden hatását visszavonhatja, majd a helyes ággal folytathatja a futást.
A spekulatív végrehajtásnak egy másik, hasonló módszere is létezik. Ebben a változatban jóslás helyett a processzor egyszerűen az elágazások mindkét ágát feltétel nélkül végrehajtja, majd a végre nem hajtandó utasítások eredményeit eldobja, hatásukat visszavonja, a ténylegesen szükséges utasítások eredményeit és hatásait pedig véglegesíti, azaz a homokozóból átmásolja a processzor minden más egysége számára elérhető munkaterületre.
Ezeknek az optimalizációs technikáknak az ismeretében már megérthetjük a Spectre és a Meltdown hibák kihasználásának mikéntjét. Egyben rácsodálkozhatunk arra is, hogy miért van a Spectre hivatalos logójában pont egy faág a szellemfigura kezében.
Meltdown: Itt a piros, hol a piros – bitekkel
A két hiba közül ez az egyszerűbb felépítésű, kevésbé általános, könnyebben tényleges rosszindulatú kóddá alakítható, és talán egy kicsivel könnyebben be is foltozható. A probléma az érintett, főleg Intel gyártmányú processzorok spekulatív és sorrenden kívüli végrehajtásában gyökerezik. Nevesen, amikor egy program megpróbál olyan memóriaterületről olvasni, amelyhez nincsen jogosultsága, akkor a processzor minden esetben elkezdi az olvasást spekulatívan. A jogosultságellenőrzés ezzel egyidőben, a tényleges olvasástól függetlenül kezdődik el. Ha utólag kiderül, hogy az utasítás nem olvashatja (pontosabban nem olvashatta volna) az adott memóriacímet, akkor a processzor eldobja az olvasás eredményeként kapott adatot, és hibát dob a memóriavédelmet megsértő programnak. Ezt a folyamatot hívják rollback-nek, visszavonásnak.
Eddig ez mind szép és jó, viszont az utolsó lépésből, a jogosulatlan olvasás eredményének eldobásából kimaradt egy részlet. A már említett caching mechanizmus automatikusan betölti a gyorsítótárba a spekulatív módon olvasott adatokat is, viszont ez a cache-ben lévő adat nem veszi figyelembe a jogosultságkezelést, és az azt követő visszavonást, az eredmények esetleges eldobását. Másképp fogalmazva: ha a processzor észrevesz egy jogosulatlan olvasást, és rollback-el, az olvasott adatokat a cache-ből mégsem törli, tehát azok egy ideig még mindenképp benne maradnak.
Ez önmagában nem lenne probléma, mert a cache-t sem lehet közvetlenül kiolvasni – az a CPU-n belül, egy jól védett, elszigetelt helyen van. A cache-ből való olvasás relatív gyorsasága a processzor egy másik képességével kombinálva viszont információt szivárogtathat ki. Nézzük, hogyan!
Amikor egy CPU-t arra utasítunk, hogy olvasson a memóriából, akkor a kiolvasandó adat címét többféleképpen adhatjuk meg. Ennek az egyik módja az úgynevezett indirekt címzés, amely egymás után egyből két olvasást végez, az alábbi módon. Az olvasási utasítás tartalmaz egy címet, és a processzor először ennek a tartalmát olvassa ki. Az így betöltött adatot azután ismét memóriacímként értelmezi, és immár erről a frissen kapott címről fog még egyet olvasni. Ennek az olvasásnak az eredménye lesz az utasítás tényleges eredménye.
Képzeljük most el, hogy például az 1000-es címtől kezdődően van egy terület a memóriában, amit nincs jogosultságunk olvasni, és 0-tól 999-ig pedig van egy másik régió, amit viszont olvashatunk. Tegyük fel, hogy az 1000-es címen lévő bájt értéke 42. Adjunk ki most egy olyan utasítást a processzornak, hogy “indirekt címzéssel olvasd ki az 1000-es címen lévő memóriacímet, majd erről a címről olvass ki egy bájtot”. Mi történik ekkor? Nos, a processzor elkezdi vágrehajtani ezt az utasítást. Olvas az 1000-es címről, ennek ez eredménye 42 lesz. A 42-t memóriacímként értelmezve, most a 42-es címről fog olvasni. Az, hogy ennek mi az eredménye, számunkra mindegy, a lényeg, hogy ezáltal a 42-es címen lévő bájt tartalma bekerült a cache-be. Ezek után természetesen a processzor észreveszi, hogy nincs jogosultságunk az 1000-es címet olvasni, így a programunk kap egy hibajelzést.
Ha azonban ezt a hibajelzést lekezeljük, és utána elkezdjük 0-tól 255-ig – ezek egy bájt lehetséges értékei – végigolvasni az összes memóriacímet, akkor azt fogjuk tapasztalni, hogy minden címnek a kiolvasása mondjuk 100 órajelciklust vesz igénybe, kivéve a 42-es címét, mert ennek a kiolvasása csak 5 órajelciklus. Ezeket az olvasási időket a programunkban megmérve levonhatjuk azt a következtetést, hogy a 42-es memóriacella tartalma már a cache-ben volt, tehát az előző, 1000-es címről való olvasás köztes eredménye 42 kellett, hogy legyen, azaz megállapítottuk egy általunk elvileg nem olvasható memóriacím tartalmát!
Természetesen ez egy erősen leegyszerűsített modellje a támadásnak. A Meltdown például akkor is működik, ha nem pont a 0-tól kezdődő memóriaterülethez van jogosultságunk (sőt, a valóságban általában a 0-tól kezdődő néhány ezer címet egyetlen program sem olvashatja), mert a gyakorlatban az indirekt címzésű olvasási utasítások megadhatnak egy tetszőleges offszetet is, amelyet a CPU az első olvasás eredményeként kapott memóriacímhez hozzáad. Továbbá, szintén teljesítmény- és sebességnövelési okokból, a modern rendszerek nem bájtonként, hanem nagyobb egységenként, úgynevezett oldalak (memory page) segítségével kezelik a memóriát, amelyeknek a jellemző mérete 4 kB. Ezért tehát az indirekt módon olvasott címeket még ennyivel (4096-tal) is meg kell szorozni, hogy minden elvben “olvashatatlan” memóriacím más memory page-nek feleljen meg, így ha egy adott page benne van a cache-ben, akkor egyértelműen lehessen tudni, hogy a kiolvasandó, védett memóriacímnek melyik értékéhez tartozott. Végül, a támadáshoz természetesen arra is szükség van, hogy biztosan tudjuk, hogy a cache eredetileg nem tartalmazta megfigyelni kívánt memóriatartományokat. Ezt a támadó általában nagyon egyszerűen el tudja érni: a legtöbb processzorban van egy specifikusan a cache kiürítésére (“flush”) szolgáló utasítás.
Spectre: egy spekulatív változat
Amíg a Meltdown a sorrenden kívüli végrehajtást használja arra, hogy a gyorsítótárba töltsön adatokat, addig a Spectre támadás a spekulatív végrehajtást és a branch prediction-t veszi rá erre. A Spectre név valójában több hasonló, a pontos technikai részletekben kicsit különböző támadást takar. Ezek közül a legegyszerűbben érthető a “bounds check bypass”, azaz tömbindex-ellenőrzést megkerülő variáns. Ez a következőképpen működik.
Adott egy tömb, azaz összefüggő memóriablokk, amelyben több adatelemet tárolhatunk. Ennek van egy eleje, az első elem címe, és egy vége, ami pedig az utolsó elem címe. Az elemek elérése indexekkel történik: az első elem indexe 0, az utolsó elem indexe pedig a tömb mérete mínusz egy. Egy programban mindig fontos ellenőrizni, hogy a tömbindexek ezen határokon belül esnek-e, különben a program hibás adatokat olvashat. (Ez bizonyos nyelvekben automatikusan megtörténik, míg más nyelvekben a programozónak saját magának kell elvégeznie az ellenőrzést.) Példának okáért, egy hibás indexről való olvasás által egy weboldalon futó JavaScript kód akár a böngészőben használt titkosítási kulcsokhoz is hozzáférhet.
Sajnos azonban a spekulatív végrehajtás ezeket a tömbhatár-ellenőrzéseket is támadhatóvá teszi. A támadó rosszindulatú kódja úgy választ meg egy tömbindexet, hogy az ezzel való memóriaelérés valamilyen érzékeny adatot töltsön be. Például két egymás utáni, 4-4 elemű tömb esetén, amelyek közül a második egy titkosítási kulcsot tartalmaz, az első tömböt megpróbálhatjuk a – helytelen – 4, 5, 6 vagy 7 indexekkel elérni. Egy helyesen működő programban ez nem sikerülhet az indexellenőrzés miatt (az első tömb érvényes indexei 0 és 3 közé esnek):

Legyen például a rosszindulatú index 7, a titkos kulcs utolsó elemének kibányászásához. Tegyük fel továbbá, hogy az 1. tömb mérete (jelen esetben 4) nincs a cache-ben. Ezt a már leírt módon egy speciális utasítással meg tudja oldani a rosszindulatú kód. Szükség lesz arra is, hogy maga az érzékeny adat (a példában a 2. tömb) viszont benne legyen a cache-ben. Ezt is egyszerűen meg lehet oldani például azzal, ha valamilyen legitim módon használjuk. Példánkban a JavaScript kód megkérhetné a böngészőt egy HTTPS kérés küldésére, amihez annak be kell töltenie a titkosítási kulcsokat.
Ezután kezdődhet a tényleges támadás első, betanítási fázisa. Ekkor a rosszindulatú kód eleinte nagyon sokszor érvényes indexekkel címzi az 1. tömböt, így a CPU branch predictor áramköre megjegyzi, hogy a tömböt indexelő, majd az indexnek megfelelő memóriacímről olvasó utasítások jó eséllyel sikerülni fognak.
A második fázisban a sok érvényes indexelés után a támadó kód egyszercsak kiüríti az 1. tömb méretét a cache-ből, majd gyorsan megpróbálja a hibás indexszel, jelen esetben 7-tel címezni a tömböt. Emiatt az indexellenőrzés ismét kiolvassa az 1. tömb méretét, ami egy úgynevezett cache miss-t fog eredményezni: mivel a méret nincs a cache-ben, ezért azt a RAM-ból kell olvasni, ami sok időt vesz igénybe. Ez alatt a várakozás alatt az előzőleg betanított branch predictor azt fogja feltételezni, hogy az index érvényes volt, tehát meg fogja kérni a processzort, hogy olvassa ki a 7. indexen lévő elemet, ami a titkos kulcsunk részét képezi. Mivel a kulcs a gyorsítótárban van, ez a betöltés sokkal gyorsabb, és már akkor megtörténik, miközben az 1. tömb mérete még csak érkezőfélben van a memóriából.
Ha tehát ebben az időintervallumban – amit a Project Zero blogbejegyzésében “mis-speculation window”, azaz spekulációs hibaablak néven említenek – a kód következő lépésként ugyanazzal az indirekt címzési trükkel él, mint amit a Meltdown esetében már láttunk, akkor hasonló módszerrel ki tudja szivárogtatni a cache állapotán keresztül azt, hogy mi volt a spekulatívan kiolvasott szám. Mire a tömbindex ellenőrzéséhez szükséges adat, azaz az 1. tömb hossza, megérkezik, és a kód rájön, hogy igazából rossz helyről olvasott (volna), addigra a titkos adathoz tartozó memóriatartomány már rég betöltődött a cache-be.

Így védekezhetünk
Amint az a részletesebb magyarázatokból is remélhetőleg jól látszik, ezek a támadások olyan hibákon alapulnak, amelyeket nem igazán lehet teljes mértékben egy egyszerű szoftverfrissítéssel megoldani. A helyzet a Meltdown esetében a könnyebb. Az operációs rendszereket át lehet írni olyan módon, hogy teljesen külön kezeljék az egyes programok és a kernel memóriáját, ezzel elkerülve, hogy egy, a Meltdown-t kihasználó program a kernel érzékeny adatait ki tudja olvasni. Sajnos ennek ára is van: innentől kezdve minden egyes alkalommal, amikor egy program egy alacsony szintű, közvetlenül a kernel által nyújtott funkciót (úgynevezett rendszerhívást) akar elérni, akkor a rendszernek oda-vissza váltania kell a program és a kernel memóriája között. Ez a sok rendszerhívást végző programok futását akár 50 százalékkal is lelassíthatja.
A Spectre sokkal nehezebben javítható. Bizonyos kihasználási módszerei ellen léteznek szoftveres megoldások, de az általános eset ellen csak az nyújtana teljeskörű védelmet, ha egyszerűen új elveken működő processzorokat terveznének és gyártanának a hardvercégek. Ez sem könnyű, sem gyors nem lesz. Azonban fontos megjegyezni, hogy ennek ellenére egyszerű felhasználóként is érdemes például minden biztonsági frissítést telepíteni. Feltörhetetlen rendszer úgysem létezik: a lényeg, hogy minél kisebb támadási felületet nyújtsunk a rosszindulatú beavatkozóknak, és ezekkel is minél nehezebb dolguk legyen. Mindemellett továbbra is tartsuk magunkat ahhoz az általános gyakorlathoz, hogy kizárólag megbízható forrásból származó, például App Store-os alkalmazásokat használunk. (A paranoiásabbak a nyílt forráskódú szoftvereket akár saját maguknak is lefordíthatják forrásból, az előre összerakott telepítőcsomagok használata helyett.)
Merre tovább?
Az ARM processzorokra fejlesztő programozók számára a gyártó kiadott egy útmutatót, amivel mindenki ellenőrizheti a saját kódját, és megkeresheti, hogy hol vannak benne esetleg olyan kódrészletek, amelyek könnyítik a Meltdown és a Spectre kihasználását. Az útmutató arra vonatkozó segítséget is tartalmaz, hogy hogyan érdemes átírni a sérülékeny kódokat biztonságosabbra. Ezt értelemszerűen az iOS-fejlesztő kollégáknak érdemes lehet átolvasni, hiszen az iOS is ARM-alapú processzorokon fut. Habár ezeket az Apple módosította, a fentiek alapján sajnos nem mentesek a két sérülékenységtől.
Érdeklődő olvasóinknak ajánljuk emellett a Computerphile sorozat idevágó epizódját. Ebben szakértők bevonásával igyekeznek közérthetően elmagyarázni egy-egy jelenséget az informatika köréből, jelen esetben a Meltdown és a Spectre alapelveivel kapcsolatban:




8 Comments
No végre egy pontos, részletes magyar nyelvű cikk ezekről, köszi! Szépen meg lett fogalmazva, szerintem egy laikus is simán meg tudja érteni. Sajnos hallottam már olyat, hogy felhívta az egyik ismerősömet a másik, aki azt hallotta a tévében, hogy ne frissítsen, mert belassul tőle a gépe. Ha mindenhol így le lenne írva, akkor talán az ilyen ostobaságok nem terjednének… (Btw. az SZTE-n elágazásjövendölésnek hívják a branch predictiont, bár az se jobb)
+1 a Computerphile embedért. 🙂
@Thomastopies: Örölök neki, hogy tetszett! 🙂 igen, itt kifejezetten az lenne a cél, hogy nem-informatikusok számára is érthető legyen a magasabb szinten a hibák oka.
Jaj, az elágazásjövendölés még jobban fáj. Az én kedvenc egyetemi magyar terminológiám a “hasítótábla” (hash table) és az “egykeminta” (singleton pattern). Miért kell…? 😀
Basszus ezt még így sem értem ???? nade visszaadja az intel a pénzem vagy sem, hogy vehessek AMD-t? ????
@H2CO3: Hú, ez nagyon jó lett! 🙂
Bár kissé hosszú, és valószínű emiatt maradt is benne egy kis következetlenség: az utolsó előtti bekezdésben (Így védekezhetünk) többször is emlegetve van a kernel, amitől a Meltdown valójában veszélyes, de magának a Meltdownnak a leírásánál a kernel egyáltalán nincs megemlítve.
A Spectre-ről olvastam olyanokat, hogy az erre alkalmas CPU-kon mikrokód-update-tel (tkp. BIOS frissítéssel) javítható. Az x64-es CPU-k például alkalmasak, de minden egyes CPU verzióhoz külön elő kell állítani az update-et, így az Intel csak az utóbbi 5 évben forgalomba került processzortípusokhoz fejlesztette ki ezeket. Érdemes körülnézni az alaplap gyártók weboldalán, az ASUS például már közzé is tette a frissítéseket.
@rgbx: Köszönöm! És jogos. Mostmár valószínűleg nem is lesz benne a kernel az elejénél. Elég baj az is, ha _valamilyen_ memóriát tudunk jogosulatlanul olvasni, a végén meg plot twist gyanánt úgyis kiderül, hogy ja amúgy kernelmemória… A magyarázatban pedig a (magasabb szintű) működési mechanizmus a lényeg technikai szempontból, és így is épp elég hosszúra sikerült a cikk 😀
@Jadeye kolléga felvetette egyébként, miközben átnézte, hogy vajon miért csak hardveresen lehet ezt javítani? Én azt válaszoltam neki, hogy ha elég flexibilis lenne az architektúra, akkor szerintem meg lehetne az unprivileged spekulatív olvasást tiltani mikrokódból is, de mivel nálam sokkal okosabb szakemberek írták, hogy “nem lehet”, ezért egyelőre inkább elhiszem nekik. De ezek szerint tévedtem; utána fogok nézni, és remélem, bele tudunk még egy rövid bekezdést iktatni a cikkbe erről, mert azért mégis elég fontos lenne, hogy minél többen tudjanak erről, ha már lehetséges…
ööö, skynet akkor most sem fog bennünket legyakni?
Köszi! “Simán” érthető volt. Eddig nem figyeltem és nem is érdekelt (eztán sem fog, hisz nem tudok mit tenni a frissítésen kívül) de legalább értem, mi hogyan megy, miért olyan nagy baj ez.
Klassz cikk volt! Kösz még1x!
@dzsega: Köszi a pozitív visszajelzést, örülök, hogy hasznos volt a cikk!